1. Основные структуры данных
1. Основные структуры данных
Программируя решение любой задачи, необходимо выбрать уровень абстрагирования. Иными словами, определить множество данных, представляющих предметную область решаемой задачи. При выборе следует руководствоваться проблематикой решаемой задачи и способами представления информации. Здесь необходимо ориентироваться на те средства, которые предоставляют системы программирования и вычислительная техника, на которой будут выполняться программы. Во многих случаях эти критерии не являются полностью независимыми.
Вопросы представления данных часто разбиваются на различные уровни детализации. Уровню языков программирования соответствуют абстрактные типы и структуры данных. Рассмотрим их реализацию в языке программирования Turbo-Pascal. Простейшим типом данных является переменная. Существуют несколько встроенных типов данных. Например, описание
Var
i, j : integer;
x : real;
s: string;
объявляет переменные i, j целочисленного типа, x √ вещественного и s √ строкового.
Переменной можно присвоить значение, соответствующее ее типу
I:=46;
X:=3.14;
S:=▓строка символов▓;
Такие переменные представляют собой лишь отдельные элементы. Для того чтобы можно было говорить о структурах данных, необходимо иметь некоторую агрегацию переменных. Примером такой агрегации является массив.
1.1. МассивыМассив объединяет элементы одного типа данных. Более формально его можно определить как упорядоченную совокупность элементов некоторого типа, адресуемых при помощи одного или нескольких индексов. Частным случаем является одномерный массив
Var
l : array [1..100] of integer;
В приведенном примере описан массив l, состоящий из элементов целочисленного типа. Элементы могут быть адресованы при помощи индекса в диапазоне значений от 1 до 100. В математических расчетах такой массив соответствует вектору. Массив не обязательно должен быть одномерным. Можно описать в виде массива матрицу 100*100
Var
M : array [1..100,1..100] of real;
В этом случае можно говорить уже о двумерном массиве. Аналогичным образом можно описать массив с большим числом измерений, например трехмерный
Var
M_3_d : array [0..10,0..10,0..10] of real;
Теперь можно говорить уже о многомерном массиве. Доступ к элементам любого массива осуществляется при помощи индексов как к обычной переменной.
М_3_d [0,0,10]:=0.25;
M[10,30]:=m_3_d[0,0,10]+0.5;
L[i]:=300;
Более сложным типом является запись. Основное отличие записи заключается в том, что она может объединять элементы данных разных типов.
Рассмотрим пример простейшей записи
Type
Person = record
Name: string;
Address: string;
Index: longint;
end;
Запись описанного типа объединяет четыре поля. Первые три из них символьного типа, а четвертое √ целочисленного. Приведенная конструкция описывает тип записи. Для того чтобы использовать данные описанного типа, необходимо описать сами данные. Один из вариантов использования отдельных записей √ объединение их в массив, тогда описание массива будет выглядеть следующим образом
Var
Persons : array[1..30] of person;
Следует заметить, что в Turbo-pascal эти два описания можно объединить в виде описания так называемого массива записей
Var
Persons : array[1..30] of record
Name: string;
Address: string;
Index: longint;
end;
Доступ к полям отдельной записи осуществляется через имя переменной и имя поля.
Persons[1] . Name:=▓Иванов▓;
Persons[1] . Adress:='город Санкт-Петербург ┘▓;
Persons[2] . Name:=▓Петров▓;
Persons[2] . Adress:='город Москва ┘▓;
Разумеется, что запись можно использовать в качестве отдельной переменной, для этого соответствующая переменная должна иметь тип, который присвоен описанию записи
Type
Person = record
Name: string;
Address: string;
Index: Longint;
end;
Var
Person1: person;
Begin
Person1.index:=190000;
1.3. МножестваНаряду с массивами и записями существует еще один структурированный тип √ множество. Этот тип используется не так часто, хотя его применение в некоторых случаях является вполне оправданным.
Тип множество соответствует математическому понятию множества в смысле операций, которые допускаются над структурами такого типа. Множество допускает операции объединения множеств (+), пересечения множеств (*), разности множеств (-) и проверки элемента на принадлежность к множеству (in). Множества также как и массивы объединяют однотипные элементы. Поэтому в описании множества обязательно должен быть указан тип его элементов.
Var
RGB, YIQ, CMY : Set of string;
Здесь мы привели описание двух множеств, элементами которых являются строки. В отличие от массивов и записей здесь отсутствует возможность индексирования отдельных элементов.
CMY:= [▒M ▓,▓C ▓,▓Y ▓];
RGB:= [▒R▓,▓G▓,▓B▓];
YIQ:=[ ▒Y ▓,▓Q ▓,▓I ▓];
Writeln (▒Пересечение цветовых систем RGB и CMY ▓, RGB*CMY);
Writeln (▒Пересечение цветовых систем YIQ и CMY ▓,YIQ*CMY);
Операции выполняются по отношению ко всей совокупности элементов множества. Можно лишь добавить, исключить или выбрать элементы, выполняя допустимые операции.
1.4. Динамические структуры данных
Мы ввели базовые структуры данных: массивы, записи, множества. Мы назвали их базовыми, поскольку из них можно образовывать более сложные структуры. Цель описания типа данных и определения некоторых переменных как относящихся к этому типу состоит в том, чтобы зафиксировать диапазон значений, присваиваемых этим переменным, и соответственно размер выделяемой для них памяти. Поэтому такие переменные называются статическими. Однако существует возможность создавать более сложные структуры данных. Для них характерно, что в процессе обработки данных изменяются не только значения переменных, но и сама их структура. Соответственно динамически изменяется и размер памяти, занимаемый такими структурами. Поэтому такие данные получили название данных с динамической структурой.
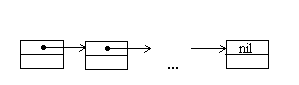
1.4.1. Линейные спискиНаиболее простой способ связать некоторое множество элементов - это организовать линейный список. При такой организации элементы некоторого типа образуют цепочку. Для связывания элементов в списке используют систему указателей. В рассматриваемом случае любой элемент линейного списка имеет один указатель, который указывает на следующий элемент в списке или является пустым указателем, что означает конец списка.
Рис. 1.1. Линейный список (связанный список)
В языке Turbo Pascal предусмотрены два типа указателей √ типизированные и не типизированные указатели. В случае линейного списка описание данных может выглядеть следующим образом.
type
element = record
data:string;
next: pointer;
end;
var
head: pointer;
current, last : ^element;
В данном примере элемент списка описан как запись, содержащая два поля. Поле data строкового типа служит для размещения данных в элементе списка. Другое поле next представляет собой не типизированный указатель, который служит для организации списковой структуры.
В описании переменных описаны три указателя head, last и current. Head является не типизированным указателем. Указатель current является типизированным указателем, что позволяет через него организовать доступ к полям внутри элемента, имеющего тип element. Для объявления типизированного указателя обычно используется символ ^, размещаемый непосредственно перед соответствующим типом данных. Однако описание типизированного указателя еще не означает создание элемента списка. Рассмотрим, как можно осуществить создание элементов и их объединение в список.
В системе программирования Turbo Pascal для размещения динамических переменных используется специальная область памяти ⌠heap-область■. Heap-область размещается в памяти компьютера следом за областью памяти, которую занимает программа и статические данные, и может рассматриваться как сплошной массив, состоящий из байтов.
Попробуем создать первый элемент списка. Это можно осуществить при помощи процедуры New
New(Current);
После выполнения данной процедуры в динамической области памяти создается динамическая переменная, тип которой определяется типом указателя. Сам указатель можно рассматривать как адрес переменной в динамической памяти. Доступ к переменной может быть осуществлен через указатель. Заполним поля элемента списка.
Current^.data:= ▓данные в первом элементе списка ▓ ;
Сurrent^.next:=nil;
Значение указателя nil означает пустой указатель. Обратим внимание на разницу между присвоением значения указателю и данным, на которые он указывает. Для указателей допустимы только операции присваивания и сравнения. Указателю можно присваивать значение указателя того же типа или константу nil. Данным можно присвоить значения, соответствующие декларируемым типам данных. Для того чтобы присвоить значение данным, после указателя используется символ ^. Поле Сurrent^.next само является указателем, доступ к его содержимому осуществляется через указатель Current.
В результате выполнения описанных действий мы получили список из одного элемента. Создадим еще один элемент и свяжем его с первым элементом.
Head:=Current;
New(last);
Last^.data:= ▓данные во втором элементе списка ▓ ;
Last^.next:=nil;
Сurrent^.next:=nil;
Непосредственно перед созданием первого элемента мы присвоили указателю Head значение указателя Current. Это связано с тем, что линейный список должен иметь заголовок. Другими словами, первый элемент списка должен быть отмечен указателем. В противном случае, если значение указателя Current в дальнейшем будет переопределено, то мы навсегда потеряем возможность доступа к данным, хранящимся в первом элементе списка.
Динамическая структура данных предусматривает не только добавление элементов в список, но и их удаление по мере надобности. Самым простым способом удаления элемента из списка является переопределение указателей, связанных с данным элементом (указывающих на него). Однако сам элемент данных при этом продолжает занимать память, хотя доступ к нему будет навсегда утерян. Для корректной работы с динамическими структурами следует освобождать память при удалении элемента структуры. В языке TurboPascal для этого можно использовать функцию Dispose. Покажем, как следует корректно удалить первый элемент нашего списка.
Head:=last;
Dispose(current);
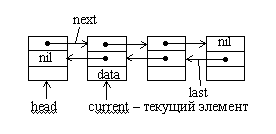
Рассмотрим пример более сложной организации списка. Линейный список неудобен тем, что при попытке вставить некоторый элемент перед текущим элементом требуется обойти почти весь список, начиная с заголовка, чтобы изменить значение указателя в предыдущем элементе списка. Чтобы устранить данный недостаток введем второй указатель в каждом элементе списка. Первый указатель связывает данный элемент со следующим, а второй √ с предыдущим. Такая организация динамической структуры данных получила название линейного двунаправленного списка (двусвязанного списка).
Рис.1.2. Двунаправленный список
Интересным свойством такого списка является то, что для доступа к его элементам вовсе не обязательно хранить указатель на первый элемент. Достаточно иметь указатель на любой элемент списка. Первый элемент всегда можно найти по цепочке указателей на предыдущие элементы, а последний - по цепочке указателей на следующие. Но наличие указателя на заголовок списка в ряде случаев ускоряет работу со списком.
Приведем пример программы, которая выполняет следующие операции с двунаправленным линейным списком:
добавление (справа и слева от текущего);
удаление (справа и слева от текущего);
поиск;
вывод списка.
program;
type element = record
data:string;
last, next: pointer;
end;
var
i,n: integer;
head: pointer;
current, pnt, pnt2: ^element;
s:string;
begin
new(current);
head:=current;
current^.data:=head;
current^.next:=nil;
current^.last:=nil;
repeat
writeln(▒1 √ сделать текущим▓);
writeln(▒2 √ список элементов▓);
writeln(▒3 √ добавить справа▓);
writeln(▒4 √ добавить слева▓);
writeln(▒5 √ удалить текущий▓);
writeln(▒6 √ удалить справа от текущего▓);
writeln(▒7 √ удалить слева от текущего▓);
writeln(▒0 √ выход▓);
writeln(▒текущий элемент: ▒, current^.data);
readln(n);
if n=1 then
{Выбор нового текущего элемента}
begin
writeln(▒▓); readln(s);
pnt:=head;
repeat
if pnt^.data=s then current:=pnt;
pnt:=pnt^.next;
until pnt=nil;
end;
if n=2 then
{Вывод всех элементов}
begin
pnt:=head; i:=1
repeat
writeln(i, ▒ √ ▒, pnt^.data);
pnt:=pnt^.next;
i:=i+1;
until pnt=nil;
end;
if n=3 then
{Добавление нового элемента справа от текущего}
begin
writeln(▒элемент▓); readln(s);
new(pnt);
pnt^.data:=s;
pnt^.last:=current;
pnt^.next:=current^.next;
pnt2:=current^.next;
if not(pnt2=nil) then pnt2^.last:=pnt;
end;
if n=4 then
{Добавление нового элемента слева от текущего}
begin
writeln(▒элемент▓); readln(s);
new(pnt);
pnt^.data:=s;
pnt^.last:=current^.last;
pnt^.next:=current;
pnt2:=current^.last;
if not(pnt2=nil) then pnt2^.next:=pnt;
end;
if n=5 and not(current=head) then
{Удаление текущего элемента}
begin
pnt:=current^.last;
pnt^.next:=current^next;
pnt2:=current^.next;
if not(pnt2=nil) then pnt2^.last:=current^.last;
dispose(current);
end;
if n=6 and not(current^.next=nil) then
{Удаление элемента справа от текущего}
begin
pnt:=current^.next;
current^.next:=pnt^next;
pnt2:=pnt^.next;
if not(pnt2=nil) then pnt2^.last:=current;
dispose(pnt);
end;
if n=7 and not(current^.last=head) and not(current^.last=nil) then
{Удаление элемента слева от текущего}
begin
pnt:=current^.last;
current^.last:=pnt^.last;
pnt2:=pnt^.last;
if not(pnt2=nil) then pnt2^.next:=current;
dispose(pnt);
end;
until n=0;
end.
В данной программе реализован алгоритм поиска элемента в списке (сделать текущим). В процессе поиска происходит обход с начала списка. Наличие указателя на заголовок списка ускоряет процесс поиска, так как не требуется сначала найти первый элемент, а затем - сделать обход списка.
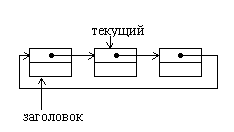
1.4.2. Циклические спискиЛинейные списки характерны тем, что в них можно выделить первый и последний элементы, причем для однонаправленного линейного списка обязательно нужно иметь указатель на первый элемент.
Циклические списки также как и линейные бывают однонаправленными и двунаправленными. Основное отличие циклического списка состоит в том, что в списке нет пустых указателей.
Рис.1.3. Однонаправленный циклический список
Последний элемент списка содержит указатель, связывающий его с первым элементом. Для полного обхода такого списка достаточно иметь указатель только на текущий элемент.
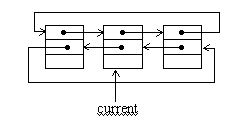
В двунаправленном циклическом списке система указателей аналогична системе указателей двунаправленного линейного списка.
Рис.1.4. Двунаправленный циклический список
Двунаправленный циклический список позволяет достаточно просто осуществлять вставки и удаления элементов слева и справа от текущего элемента. В отличие от линейного списка, элементы являются равноправными и для выделения первого элемента необходимо иметь указатель на заголовок. Однако во многих случаях нет необходимости выделять первый элемент списка и достаточно иметь указатель на текущий элемент. Рассмотрим пример программы, которая осуществляет следующие операции с двунаправленным циклическим списком:
добавление (справа и слева от текущего);
удаление (справа и слева от текущего);
поиск;
вывод списка.
program;
type element = record
data:string;
last, next: pointer;
end;
var
i,n: integer;
point: pointer;
current, pnt, pnt2: ^element;
s:string;
begin
new(current);
current^.data:=▓first▓;
current^.next:=current
current^.last:=current;
repeat
writeln(▒1 √ сделать текущим▓);
writeln(▒2 √ список элементов▓);
writeln(▒3 √ добавить справа▓);
writeln(▒4 √ добавить слева▓);
writeln(▒5 √ удалить текущий▓);
writeln(▒6 √ удалить справа от текущего▓);
writeln(▒7 √ удалить слева от текущего▓);
writeln(▒0 √ выход▓);
writeln(▒текущий элемент: ▒, current^.data);
readln(n);
if n=1 then
{Выбор нового текущего элемента}
begin
writeln(▒▓); readln(s);
pnt:=current; point:=current;
repeat
if pnt^.data=s then current:=pnt;
pnt:=pnt^.next;
until pnt=point;
end;
if n=2 then
{Вывод всех элементов}
begin
pnt:=curent; i:=1
repeat
writeln(i, ▒ √ ▒, pnt^.data);
pnt:=pnt^.next; i:=i+1;
until pnt=current;
end;
if n=3 then
{Добавление нового элемента справа от текущего}
begin
writeln(▒элемент▓); readln(s);
new(pnt);
pnt^.data:=s;
pnt^.last:=current;
pnt^.next:=current^.next;
pnt2:=current^.next;
pnt2^.last:=pnt;
current^.next:=pnt;
end;
if n=4 then
{Добавление нового элемента слева от текущего}
begin
writeln(▒элемент▓); readln(s);
new(pnt);
pnt^.data:=s;
pnt^.last:=current^.last;
pnt^.next:=current;
pnt2:=current^.last;
pnt2^.next:=pnt;
end;
if n=5 and not(current^.next=current) then
begin
{Удаление текущего элемента}
pnt:=current^.last;
pnt2^.next:=current^next;
pnt2^.last:=current^.last;
pnt2:=current^next;
dispose(current);
current:=pnt2;
end;
if n=6 and not(current^.next=current) then
{Удаление элемента справа от текущего}
begin
pnt:=current^.next;
current^.next:=pnt^next;
pnt2:=pnt^.next;
pnt2^.last:=current;
dispose(pnt);
end;
if n=7 and not(current^.next=current)then
{Удаление элемента слева от текущего}
begin
pnt:=current^.last;
current^.last:=pnt^.last;
pnt2:=pnt^.last;
pnt2^.next:=current;
dispose(pnt);
end;
until n=0;
end.
В данном примере указатель на первый элемент списка отсутствует. Для предотвращения зацикливания при обходе списка во время поиска указатель на текущий элемент предварительно копируется и служит ограничителем.
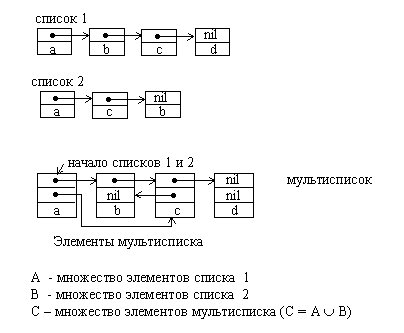
1.4.3. МультиспискиИногда возникают ситуации, когда имеется несколько разных списков, которые включают в свой состав одинаковые элементы. В таком случае при использовании традиционных списков происходит многократное дублирование динамических переменных и нерациональное использование памяти. Списки фактически используются не для хранения элементов данных, а для организации их в различные структуры. Использование мультисписков позволяет упростить эту задачу.
Мультисписок состоит из элементов, содержащих такое число указателей, которое позволяет организовать их одновременно в виде нескольких различных списков. За счет отсутствия дублирования данных память используется более рационально.
Рис.1.5. Объединение двух линейных списков в один мультисписок.
Экономия памяти √ далеко не единственная причина, по которой применяют мультисписки. Многие реальные структуры данных не сводятся к типовым структурам, а представляют собой некоторую комбинацию из них. Причем комбинируются в мультисписках самые различные списки √ линейные и циклические, односвязанные и двунаправленные.
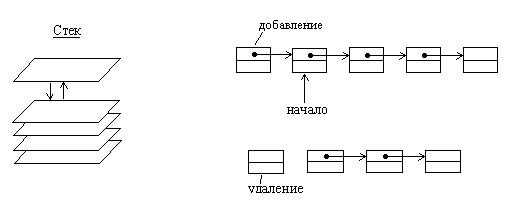
1.5. Представление стека и очередей в виде списков 1.5.1. СтекСтек представляет собой структуру данных, из которой первым извлекается тот элемент, который был добавлен в нее последним. Стек как динамическую структуру данных легко организовать на основе линейного списка. Для такого списка достаточно хранить указатель вершины стека, который указывает на первый элемент списка. Если стек пуст, то списка не существует и указатель принимает значение nil.
Рис.1.6. Организация стека на основе линейного списка.
Приведем пример программы, реализующей стек как динамическую структуру.
Program stack;
type
element=record
data:string;
next:pointer;
end;
var
n: integer;
current:^element;
pnt:^element;
procedure put_element(s:string); {занесение элемента в стек}
begin
new(pnt);
x^.data:=s;
x^.next:=current;
current:=pnt;
end;
procedure get_element(var s:string); {получение элемента из стека}
begin
if current=nil then s:=▓пусто▓ else
begin
pnt:=current;
s:=pnt^.data;
current:=pnt^.next;
dispose(pnt);
end;
end;
{------------program--------------}
begin
current:=nil;
repeat
writeln(▒1 √ добавить в стек▓);
writeln(▒2 √ удалить из стека▓);
writeln(▒0 √ выход▓);
readln(n);
if n=1 then
begin
write(▒элемент ? ▓);
readln(s);
put_element(s);
end;
if n=2 then
begin
get_element(s);
writeln(s);
end;
until n=0;
end.
В программе добавление нового элемента в стек оформлено в виде процедуры put_element, а получение элемента из стека √ как процедура get_element.
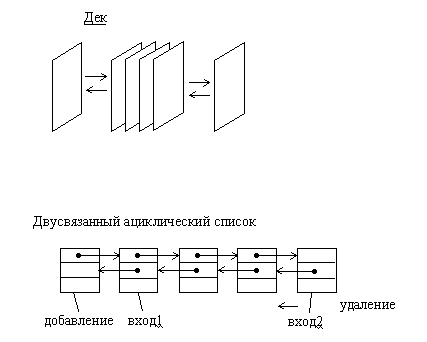
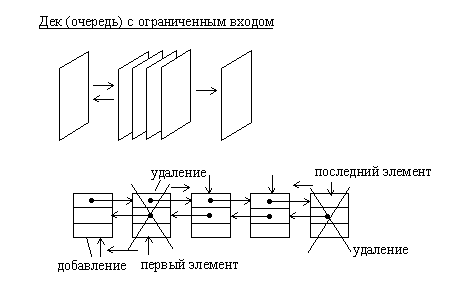
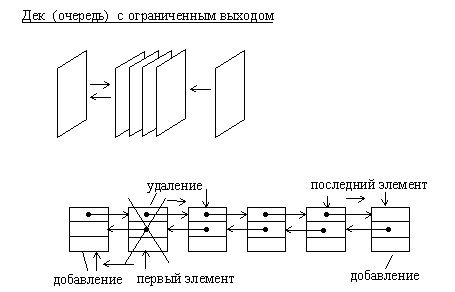
1.5.2. ОчередиДек или двусторонняя очередь, представляет собой структуру данных, в которой можно добавлять и удалять элементы с двух сторон. Дек достаточно просто можно организовать в виде двусвязанного ациклического списка. При этом первый и последний элементы списка соответствуют входам (выходам) дека.
Рис.1.7. Организация дека на основе двусвязанного линейного списка
Рис.1.8. Организация дека на основе двусвязанного линейного списка
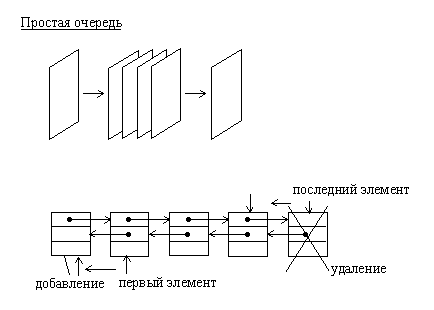
Простая очередь может быть организована на основе двусвязанного линейного списка. В отличие от дека простая очередь имеет один вход и один выход. При этом тот элемент, который был добавлен в очередь первым, будет удален из нее также первым.
Рис.1.9. Организация дека с ограниченным входом на основе двусвязанного линейного списка
Рис.1.10. Организация дека с ограниченным выходом на основе двусвязанного линейного списка
Очередь с ограниченным входом или с ограниченным выходом также как дек или очередь можно организовать на основе линейного двунаправленного списка.
Разновидностями очередей являются очередь с ограниченным входом и очередь с ограниченным выходом. Они занимают промежуточное положение между деком и простой очередью.
Причем дек с ограниченным входом может быть использован как простая очередь или как стек.