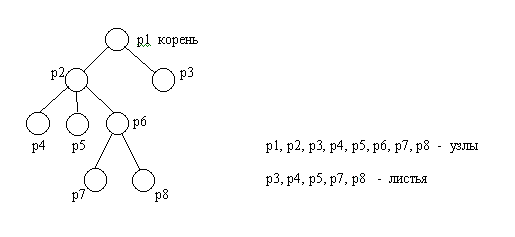Теория графов является важной частью вычислительной математики. С помощью этой теории решаются большое количество задач из различных областей. Граф состоит из множества вершин и множества ребер, которые соединяют между собой вершины. С точки зрения теории графов не имеет значения, какой смысл вкладывается в вершины и ребра. Вершинами могут быть населенными пункты, а ребрами дороги, соединяющие их, или вершинами являться подпрограммы, соединенные вершин ребрами означает взаимодействие подпрограмм. Часто имеет значение направления дуги в графе. Если ребро имеет направление, оно называется дугой, а граф с ориентированными ребрами называется орграфом.
Дадим теперь более формально основное определение теории графов. Граф G есть упорядоченная пара (V,E), где V - непустое множество вершин, E - множество пар элементов множества V, пара элементов из V называется ребром. Упорядоченная пара элементов из V называется дугой. Если все пары в Е - упорядочены, то граф называется ориентированным.
Путь - это любая последовательность вершин орграфа такая, что в этой последовательности вершина b может следовать за вершиной a, только если существует дуга, следующая из а в b. Аналогично можно определить путь, состоящий из дуг. Путь начинающийся в одной вершине и заканчивающийся в одной вершине называется циклом. Граф в котором отсутствуют циклы, называется ациклическим.
Важным частным случаем графа является дерево. Деревом называется орграф для которого :
1. Существует узел, в которой не входит не одной дуги. Этот узел называется корнем.
2. В каждую вершину, кроме корня, входит одна дуга.
С точки зрения представления в памяти важно различать два типа деревьев: бинарные и сильноветвящиеся.
В бинарном дереве из каждой вершины выходит не более двух дуг. В сильноветвящемся дереве количество дуг может быть произвольным.
4.1. Бинарные деревьяБинарные деревья классифицируются по нескольким признакам. Введем понятия степени узла и степени дерева. Степенью узла в дереве называется количество дуг, которое из него выходит. Степень дерева равна максимальной степени узла, входящего в дерево. Исходя из определения степени понятно, что степень узла бинарного дерева не превышает числа два. При этом листьями в дереве являются вершины, имеющие степень ноль.
Рис.4.1. Бинарное дерево
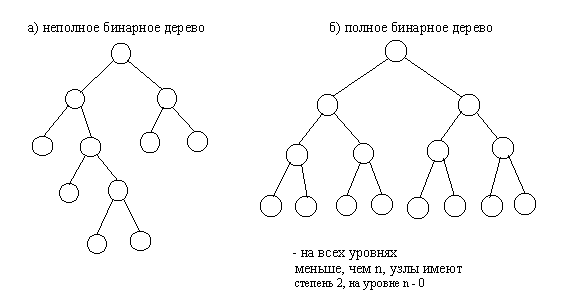
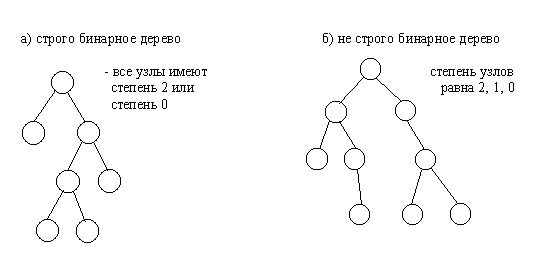
Другим важным признаком структурной классификации бинарных деревьев является строгость бинарного дерева. Строго бинарное дерево состоит только из узлов, имеющих степень два или степень ноль. Нестрого бинарное дерево содержит узлы со степенью равной одному.
Рис.4.2. Полное и неполное бинарные деревья
Рис.4.3. Строго и не строго бинарные деревья
4.2. Представление бинарных деревьев
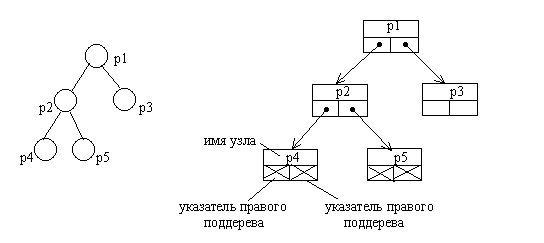
Бинарные деревья достаточно просто могут быть представлены в виде списков или массивов. Списочное представление бинарных деревьев основано на элементах, соответствующих узлам дерева. Каждый элемент имеет поле данных и два поля указателей. Один указатель используется для связывания элемента с правым потомком, а другой √ с левым. Листья имеют пустые указатели потомков. При таком способе представления дерева обязательно следует сохранять указатель на узел, являющийся корнем дерева.
Можно заметить, что такой способ представления имеет сходство с простыми линейными списками. И это сходство не случайно. На самом деле рассмотренный способ представления бинарного дерева является разновидностью мультисписка, образованного комбинацией множества линейных списков. Каждый линейный список объединяет узлы, входящие в путь от корня дерева к одному из листьев.
Рис.4.4. Представление бинарного дерева в виде списковой структуры
Приведем пример программы, которая осуществляет создание и редактирование бинарного дерева, представленного в виде списковой структуры
program bin_tree_edit;
type node=record
name: string;
left, right: pointer;
end;
var
n:integer;
pnt_s,current_s,root: pointer;
pnt,current:^node;
s: string;
procedure node_search (pnt_s:pointer; var current_s:pointer);
{Поиск узла по содержимому}
var
pnt_n:^node;
begin
pnt_n:=pnt_s; writeln(pnt_n^.name);
if not (pnt_n^.name=s) then
begin
if pnt_n^.left <> nil then
node_search (pnt_n^.left,current_s);
if pnt_n^.right <> nil then
node_search (pnt_n^.right,current_s);
end
else current_s:=pnt_n;
end;
procedure node_list (pnt_s:pointer);
{Вывод списка всех узлов дерева}
var
pnt_n:^node;
begin
pnt_n:=pnt_s; writeln(pnt_n^.name);
if pnt_n^.left <> nil then node_list (pnt_n^.left);
if pnt_n^.right <> nil then node_list (pnt_n^.right);
end;
procedure node_dispose (pnt_s:pointer);
{Удаление узла и всех его потомков в дереве}
var
pnt_n:^node;
begin
if pnt_s <> nil then
begin
pnt_n:=pnt_s; writeln(pnt_n^.name);
if pnt_n^.left <> nil then
node_dispose (pnt_n^.left);
if pnt_n^.right <> nil then
node_dispose (pnt_n^.right);
dispose(pnt_n);
end
end;
begin
new(current);root:=current;
current^.name:='root';
current^.left:=nil;
current^.right:=nil;
repeat
writeln('текущий узел -',current^.name);
writeln('1-присвоить имя левому потомоку');
writeln('2-присвоить имя правому потомку');
writeln('3-сделать узел текущим');
writeln('4-вывести список всех узлов');
writeln('5-удалить потомков текущего узла');
read(n);
if n=1 then
begin {Создание левого потомка}
if current^.left= nil then new(pnt)
else pnt:= current^.left;
writeln('left ?');
readln;
read(s);
pnt^.name:=s;
pnt^.left:=nil;
pnt^.right:=nil;
current^.left:= pnt;
end;
if n=2 then
begin {Создание правого потомка}
if current^.right= nil then new(pnt)
else pnt:= current^.right;
writeln('right ?');
readln;
read(s);
pnt^.name:=s;
pnt^.left:=nil;
pnt^.right:=nil;
current^.right:= pnt;
end;
if n=3 then
begin {Поиск узла}
writeln('name ?');
readln;
read(s);
current_s:=nil; pnt_s:=root;
node_search (pnt_s, current_s);
if current_s <> nil then current:=current_s;
end;
if n=4 then
begin {Вывод списка узлов}
pnt_s:=root;
node_list(pnt_s);
end;
if n=5 then
begin {Удаление поддерева}
writeln('l,r ?');
readln;
read(s);
if (s='l') then
begin {Удаление левого поддерева}
pnt_s:=current^.left;
current^.left:=nil;
node_dispose(pnt_s);
end
else
begin {Удаление правого поддерева}
pnt_s:=current^.right;
current^.right:=nil;
node_dispose(pnt_s);
end;
end;
until n=0
end.
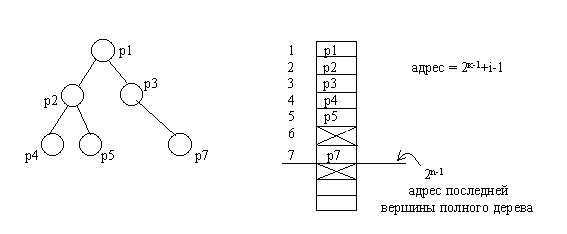
В виде массива проще всего представляется полное бинарное дерево, так как оно всегда имеет строго определенное число вершин на каждом уровне. Вершины можно пронумеровать слева направо последовательно по уровням и использовать эти номера в качестве индексов в одномерном массиве.
Рис.4.5. Представление бинарного дерева в виде массива
Если число уровней дерева в процессе обработки не будет существенно изменяться, то такой способ представления полного бинарного дерева будет значительно более экономичным, чем любая списковая структура.
Однако далеко не все бинарные деревья являются полными. Для неполных бинарных деревьев применяют следующий способ представления. Бинарное дерево дополняется до полного дерева, вершины последовательно нумеруются. В массив заносятся только те вершины, которые были в исходном неполном дереве. При таком представлении элемент массива выделяется независимо от того, будет ли он содержать узел исходного дерева. Следовательно, необходимо отметить неиспользуемые элементы массива. Это можно сделать занесением специального значения в соответствующие элементы массива. В результате структура дерева переносится в одномерный массив. Адрес любой вершины в массиве вычисляется как
адрес = 2к-1+i-1,
где k-номер уровня вершины, i- номер на уровне k в полном бинарном дереве. Адрес корня будет равен единице. Для любой вершины можно вычислить адреса левого и правого потомков
адрес_L = 2к+2(i-1)
адрес_R = 2к+2(i-1)+1
Главным недостатком рассмотренного способа представления бинарного дерева является то, что структура данных является статической. Размер массива выбирается исходя из максимально возможного количества уровней бинарного дерева. Причем чем менее полным является дерево, тем менее рационально используется память.
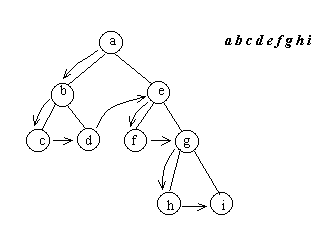
4.3. Прохождение бинарных деревьевВ ряде алгоритмов обработки деревьев используется так называемое прохождение дерева. Под прохождением бинарного дерева понимают определенный порядок обхода всех вершин дерева. Различают несколько методов прохождения.
Прямой порядок прохождения бинарного дерева можно определить следующим образом
- попасть в корень
- пройти в прямом порядке левое поддерево
- пройти в прямом порядке правое поддерево
Рис.4.6. Прямой порядок прохождения бинарного дерева
Прохождение бинарного дерева в обратном порядке можно определить в аналогичной форме
- пройти в обратном порядке левое поддерево
- пройти в обратном порядке правое поддерево
- попасть в корень
Рис.4.7. Обратный порядок прохождения бинарного дерева
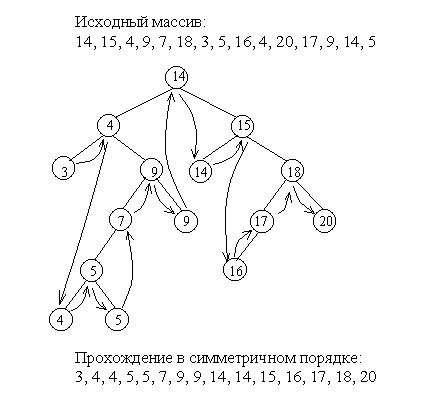
Определим еще один порядок прохождения бинарного дерева, называемый симметричным.
- пройти в симметричном порядке левое поддерево
- попасть в корень
- пройти в симметричном порядке правое поддерево
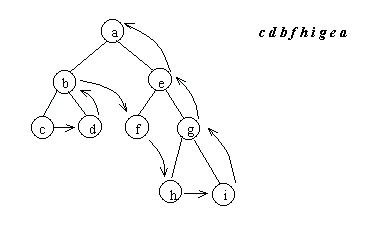
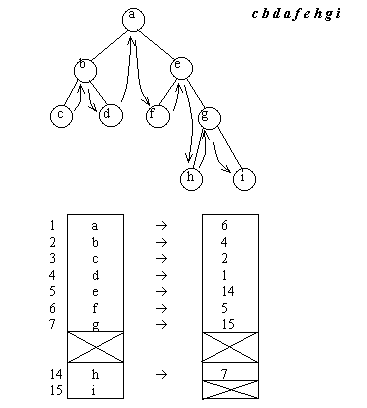
Порядок обхода бинарного дерева можно хранить непосредственно в структуре данных. Для этого достаточно ввести дополнительное поле указателя в элементе списковой структуры и хранить в нем указатель на вершину, следующую за данной вершиной при обходе дерева.
Представление деревьев в виде массивов также допускает хранение порядка прохождения дерева. Для этого вводится дополнительный массив, в который записываются адрес вершины в основном массиве, следующей за данной вершиной.
Рис.4.8. Представление симметрично прошитого бинарного дерева в виде массивов
Такие структуры данных получили название прошитых бинарных деревьев. Указатели или адреса, определяющие порядок обхода называют нитями. При этом в соответствии с порядком прохождения вершин
различают право прошитые, лево прошитые и симметрично прошитые бинарные деревья.
4.4. Алгоритмы на деревьях
4.4.1. Сортировка с прохождением бинарного дереваВ качестве примера использования прохождения бинарного дерева можно привести один из способов сортировки. Допустим, мы имеем некоторый массив и пытаемся упорядочить его элементы по возрастанию. Сама сортировка при этом распадается на две фазы
- построение дерева
- прохождение дерева
Дерево строится по следующим принципам. В качестве корня создается узел, в который записывается первый элемент массива. Для каждого очередного элемента создается новый лист. Если элемент меньше значения в текущем узле, то для него выбирается левое поддерево, если больше или равен √ правое.
Рис.4.9. Сортировка по возрастанию с прохождением бинарного дерева
Для создания очередного узла происходят сравнения элемента со значениями существующих узлов, начиная с корня.
Во время второй фазы происходит прохождение дерева в симметричном порядке. Результатом сортировки является последовательность значений элементов, извлекаемых их пройденных узлов.
Для того чтобы сделать сортировку по убыванию, необходимо изменить только условия выбора поддерева при создании нового узла во время построения дерева.
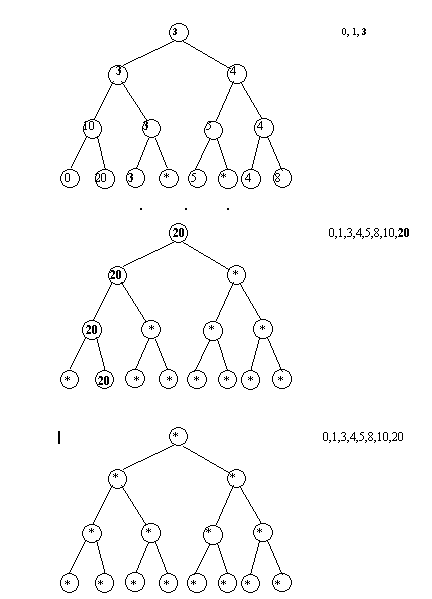
4.4.2. Сортировка методом турнира с выбываниемПриведем другой алгоритм сортировки, основанный на использовании бинарных деревьев. Данный метод получил название турнира с выбыванием. Пусть мы имеем исходный массив
10, 20, 3, 1, 5, 0, 4, 8
Сортировка начинается с создания листьев дерева. В качестве листьев бинарного дерева создаются узлы, в которых записаны значения элементов исходного массива.
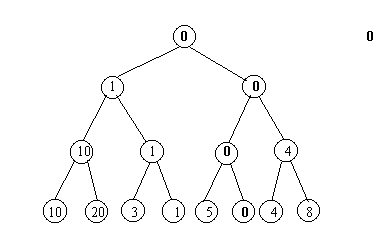
Дерево строится от листьев к корню. Для двух соседних узлов строится общий предок, до тех пор, пока не будет создан корень. В узел-предок заносится значение, являющееся наименьшим из значений в узлах-потомках.
Рис.4.10. Построение дерева сортировки
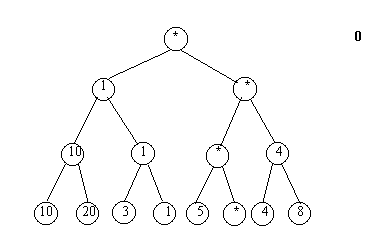
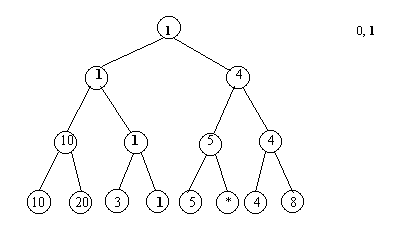
В результате построения такого дерева наименьший элемент попадает сразу в корень. Далее начинается извлечение элементов из дерева. Извлекается значение из корня. Данное значение является первым элементом в результирующем массиве. Извлеченное значение помещается в отсортированный массив и заменяется в дереве на специальный символ.
После этого происходит повторное занесение значений в родительские элементы от листьев к корню. При сравнениях специальный символ считается большим по отношению к любому другому значению.
После повторного заполнения из корня извлекается очередной элемент и итерация повторяется. Извлечения элементов продолжаются до тех пор, пока в дереве не останутся одни специальные символы.
Рис.4.11. Замена извлекаемого элемента на специальный символ
Рис.4.12. Повторное заполнение дерева сортировки
Рис.4.13. Извлечения элементов из дерева сортировки
В результате получим отсортированный массив
0, 1, 3, 4, 5, 8, 10, 20
4.4.3. Применение бинарных деревьев для сжатия информации
Рассмотрим применение деревьев для сжатия информации. Под сжатием мы будем понимать получение более компактного кода.
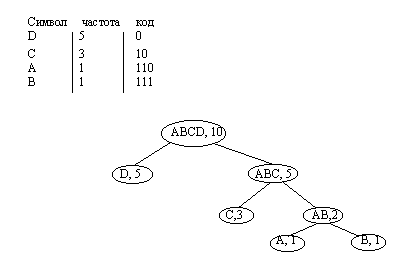
Рассмотрим следующий пример. Имеется текстовая строка S, состоящая из 10 символов
S = ABCCCDDDDD
При кодировании одного символа одним байтом для строки потребуется 10 байт.
Попробуем сократить требуемую память. Рассмотрим, какие символы действительно требуется кодировать. В данной строке используются всего 4 символа. Поэтому можно использовать укороченный код.
A 00
B 01
C 10
D 11
S = 00, 01, 10, 10, 10, 11, 11, 11, 11, 11 (20 бит)
В данном случае мы проанализировали текст на предмет использования символов. Можно заметить, что различные символы имеют различную частоту повторения. Существуют методы кодирования, позволяющие использовать этот факт для уменьшения длины кода.
Одним из таких методов является кодирование Хафмена. Он основан на использовании кодов различной длины для различных символов. Для максимально повторяющихся символов используют коды минимальной длины.
Построение кодовой таблицы происходит с использованием бинарного дерева. В корне дерева помещаются все символы и их суммарная частота повторения. Далее выбирается наиболее часто используемый символ и помещается со своей частотой повторения в левое поддерево. В правое поддерево помещаются оставшиеся символы с их суммарной частотой. Затем описанная операция проводится для всех вершин дерева, которые содержат более одного символа.
Само дерево может быть использовано в качестве кодовой таблицы для кодирования и декодирования текста. Кодирование осуществляется следующим образом. Для очередного символа в качестве кода используется путь от листа соответствующего символа к корню дерева. Причем каждому левому поддереву приписывается ноль, а каждому правому √ единица.
Рис. 4.14. Построение кодовой таблицы
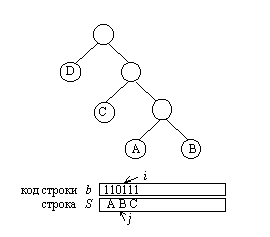
Тогда для строки S будет получен следующий код
S=11011110101000000
Длина кода составляет 17 бит, что меньше по сравнению с укороченным кодом.
Теперь рассмотрим процесс декодирования. Алгоритм распаковки кода можно сформулировать следующим образом.
Распаковка
1. i:=0, j:=0;
2. если i>n, то стоп строка распакована, иначе i:=i+1;
3. node:= root;
4. если b(i)=0, то node:=left(node), иначе node:=right(node)
5. если left(node)=0 и right(node)=0, то j:=j+1, s(j):= str(node), перейти к шагу 2, иначе i:=i+1, перейти к шагу 4
В алгоритме корень дерева обозначен как root, а Left(node) и right(node) обозначают левый и правый потомки узла node.
Рис. 4.15. Процесс распаковки кода
На практике такие способы упаковки используются не только для текстов, но и для произвольных двоичных данных. Дело в том, что любой файл можно рассматривать как последовательность байт. Тогда дерево кодирования можно построить не для символов, а для значений байт, встречающихся в кодируемом файле. Поскольку байт может принимать 256 значений, то соответствующее дерево будет иметь не более 256 листьев. В узлах дерева после его полного построения нет необходимости хранить несколько значений кодов и частоты повторения. Для кодирования и декодирования достаточно хранить только одно значение кода и только для листового узла. Поэтому такой способ представления кодовой таблицы является достаточно компактным.
Схемы кодирования подобного типа используются в программах архивации данных и сжатия растровых изображений в форматах графических файлов.
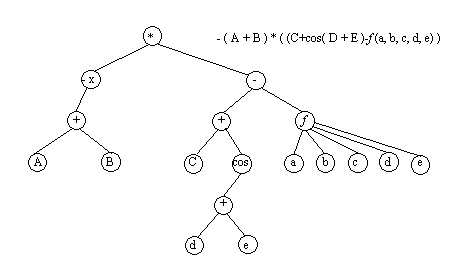
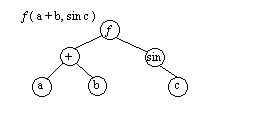
4.4.4. Представление выражений с помощью деревьевС помощью деревьев можно представлять произвольные арифметические выражения. Каждому листу в таком дереве соответствует операнд, а каждому родительскому узлу √ операция. В общем случае дерево при этом может оказаться не бинарным.
Однако если число операндов любой операции будет меньше или равно двум, то дерево будет бинарным. Причем если все операции будут иметь два операнда, то дерево окажется строго бинарным.
Рис.4.16. Представление арифметического выражения произвольного вида в виде дерева.
Рис. 4.17. Представление арифметического выражения в виде бинарного дерева
Бинарные деревья могут быть использованы не только для представления выражений, но и для их вычисления. Для того чтобы выражение можно было вычислить, в листьях записываются значения операндов.
Затем от листьев к корню производится выполнение операций. В процессе выполнения в узел операции записывается результат ее выполнения. В конце вычислений в корень будет записано значение, которое и будет являться результатом вычисления выражения.
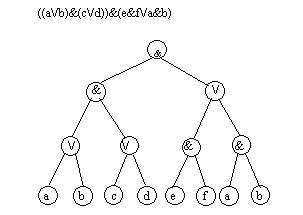
Помимо арифметических выражений с помощью деревьев можно представлять выражения других типов. Примером являются логические выражения. Поскольку функции алгебры логики определены над двумя или одним операндом, то дерево для представления логического выражения будет бинарным
Рис.4.18. Вычисление арифметического выражения с помощью бинарного дерева
Рис. 4.19. Представление логического выражения в виде бинарного дерева
4.5. Представление сильноветвящихся деревьев
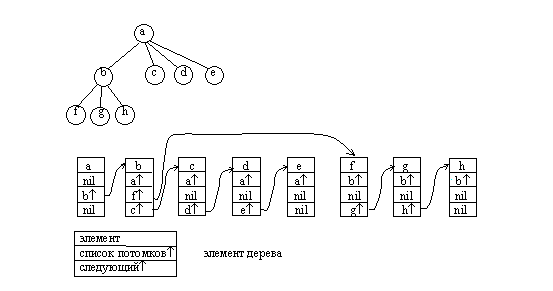
До сих пор мы рассматривали только способы представления бинарных деревьев. В ряде задач используются сильноветвящиеся деревья. Каждый элемент для представления бинарного дерева должен содержать как минимум три поля √ значение или имя узла, указатель левого поддерева, указатель правого поддерева. Произвольные деревья могут быть бинарными или сильноветвящимися. Причем число потомков различных узлов не ограничено и заранее не известно.
Тем не менее, для представления таких деревьев достаточно иметь элементы, аналогичные элементам списковой структуры бинарного дерева. Элемент такой структуры содержит минимум три поля: значение узла, указатель на начало списка потомков узла, указатель на следующий элемент в списке потомков текущего уровня. Также как и для бинарного дерева необходимо хранить указатель на корень дерева. При этом дерево представлено в виде структуры, связывающей списки потомков различных вершин. Такой способ представления вполне пригоден и для бинарных деревьев.
Представление деревьев с произвольной структурой в виде массивов может быть основано на матричных способах представления графов.
Рис.4.20. Представление сильноветвящихся деревьев в виде списков
4.6. Применение сильноветвящихся деревьевОдин из примеров применения сильноветвящихся деревьев был связан с представлением арифметических выражений произвольного вида. Рассмотрим использование таких деревьев для представления иерархической структуры каталогов файловой системы. Во многих файловых системах структура каталогов и файлов, как правило, представляет собой одно или несколько сильноветвящихся деревьев. В файловой системе MS Dos корень дерева соответствует логическому диску. Листья дерева соответствуют файлам и пустым каталогам, а узлы с ненулевой степенью - непустым каталогам.
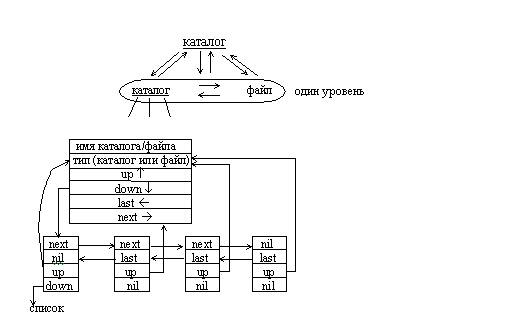
Рис.4.21. Представление логической структуры каталогов и файлов в виде сильноветвящегося дерева.
Для представления такой структуры используем расширение спискового представления сильноветвящихся деревьев. Способы представления деревьев, рассмотренные ранее, являются предельно экономичными, но не очень удобными для перемещения по дереву в разных направлениях. Именно такая задача встает при просмотре структуры каталогов. Необходимо осуществлять ⌠навигацию■ √ перемещаться из текущего каталога в каталог верхнего или нижнего уровня, или от файла к файлу в пределах одного каталога.
Для облегчения этой задачи сделаем списки потомков двунаправленными. Для этого достаточно ввести дополнительный указатель на предыдущий узел ■last■. С целью упрощения перемещения по дереву от листьев к корню введем дополнительный указатель на предок текущего узла ⌠up■. Общими с традиционными способами представления являются указатели на список потомков узла ⌠down■ и следующий узел ⌠next■.
Для представления оглавления диска служат поля имя и тип файла/каталога. Рассмотрим программу, которая осуществляет чтение структуры заданного каталога или диска, позволяет осуществлять навигацию и подсчет места занимаемого любым каталогом.
program dir_tree;
uses dos;
type node=record
name: string[50]; {Имя каталога/файла}
size: longint; {Размер файла (байт) }
node_type: char; {Тип узла (файл √'f' / каталог-'c')}
up,down: pointer; {Указатели на предка и список потомков}
l last,next: pointer; {Указатели на соседние узлы}
end;
var
n,i,l:integer;
root, current_root: pointer;
pnt, current:^node;
s : searchrec;
str: string;
procedure create_tree(local_root:pointer);
{Отображение физического оглавления диска в логическую структуру}
var
local_node, local_r_node, local_last : ^node;
procedure new_node;
{Создание нового узла в дереве каталогов и файлов}
begin
new(local_node);
local_node^.last:=local_last;
if not(local_last=nil) then local_last^.next:=local_node;
local_node^.next:=nil;
local_node^.down:=nil;
local_node^.up:=local_r_node;
if local_r_node^.down =nil then local_r_node^.down:=local_node;
local_node^.name:=local_r_node^.name+'\'+s.name;
if s.attr and Directory = 0 then local_node^.node_type:='f'
else local_node^.node_type:='c';
local_node^.size:=s.size;
local_last:=local_node;
end;
begin {Собственно процедура}
local_r_node:=local_root;
local_last:=nil;
findfirst(local_r_node^.name+'\*.*',anyfile,s);
if doserror = 0 then
begin
if (s.name<>'.') and (s.name<>'..') and (s.attr and VolumeID = 0)
then new_node;
while doserror=0 do begin
findnext(s);
if (doserror = 0) and (s.name<>'.') and (s.name<>'..') and (s.attr and VolumeID = 0)
then new_node;
end
end;
if not (local_r_node^.down=nil) then
begin
local_node:=local_r_node^.down;
repeat
if local_node^.node_type='c' then create_tree(local_node);{Рекурсия}
local_node:=local_node^.next
until local_node=nil
end
end;
procedure current_list;
{Вывод оглавления текущего каталога}
begin
current:=current_root;
writeln('текущий каталог - ', current^.name);
if current^.node_type='c'then
begin
pnt:=current^.down;
i:=1;
repeat {Проходим каталог в дереве}
writeln (i:4,'-',pnt^.name);
pnt:=pnt^.next;
i:=i+1
until pnt=nil
end;
end;
procedure down;
{Навигация в дереве каталогов. Перемещение на один уровень вниз}
begin
current:=current_root;
if not (current^.down=nil) then
begin
current:= current^.down;
writeln('номер в оглавлении'); readln; read(l);
i:=1;
while (i<l) and not (current^.next=nil) do
begin
current:=current^.next;
i:=i+1
end;
if (current^.node_type='c') and not (current^.down=nil)
then current_root:= current;
end;
end;
procedure up;
{Навигация в дереве каталогов. Перемещение на один уровень вверх}
begin
current:=current_root;
if not (current^.up=nil) then current_root:=current^.up;
end;
procedure count;
{Расчет числа файлов и подкаталогов иерархической структуры каталога}
var
n_files, n_cats :integer;
procedure count_in (local_root : pointer);
var
local_node, local_r_node: ^node;
begin
local_r_node:=local_root;
if not (local_r_node^.down=nil) then
begin
local_node:=local_r_node^.down;
repeat
if local_node^.node_type='f' then
n_files:=n_files+1
else
begin
n_cats:=n_cats+1;
count_in (local_node)
end;
local_node:=local_node^.next
until local_node=nil
end
end;
begin {Собственно процедура}
n_files:=0; n_cats:=0;
count_in (current_root);
writeln ('файлы : ',n_files, ' каталоги: ', n_cats);
end;
procedure count_mem;
{Расчет физического объема иерархической структуры каталога}
var
mem :longint;
procedure count_m_in (local_root : pointer);
var
local_node, local_r_node: ^node;
begin
local_r_node:=local_root;
if not (local_r_node^.down=nil) then
begin
local_node:=local_r_node^.down;
repeat
if local_node^.node_type='f' then
mem:=mem+local_node^.size
else
count_m_in (local_node);
local_node:=local_node^.next
until local_node=nil
end
end;
begin {Собственно процедура}
mem:=0;
count_m_in (current_root);
writeln ('mem ', mem, ' bytes');
end;
{----------основная программа----------}
begin
new(current);
{Инициализация корня дерева каталогов и указателей для навигации}
root:=current; current_root:=current;
writeln('каталог ?'); read(str); writeln(str);
current^.name:=str;
current^.last:=nil; current^.next:=nil;
current^.up:=nil; current^.down:=nil;
current^.node_type:='c';
{Создание дерева каталогов}
create_tree(current);
if current^.down=nil then current^.node_type:=' ';
repeat
{ Интерактивная навигация }
writeln ('1-список');
writeln('2-вниз');
writeln('3-вверх');
writeln('4-число файлов');
writeln('5-объем');
readln(n);
if n=1 then current_list;
if n=2 then down;
if n=3 then up;
if n=4 then count;
if n=5 then count_mem;
until n=0
end.
Для чтения оглавления диска в данной программе используются стандартные процедуры findfirst и findnext, которые возвращают сведения о первом и последующих элементах в оглавлении текущего каталога.
В процессе чтения корневого каталога строится первый уровень потомков в списковой структуре дерева. Далее процедура построения поддерева вызывается для каждого узла в корневом каталоге. Затем процесс повторяется для всех непустых какталогов до тех пор, пока не будет построена полная структура оглавления.
Все операции по просмотру содержимого каталогов и подсчету занимаемого объема производятся не с физическими каталогами и файлами, а с созданным динамическим списковым представлением их логической структуры в виде сильноветвящегося дерева.
В данном примере программы для каждого файла или каталога хранится его полное имя в MS-DOS, которое включает имя диска и путь. Если программу несколько усложнить, то можно добиться более эффективного использования динамической памяти. Для этого потребуется хранить в узле дерева только имя каталога или файла, а полое имя √ вычислять при помощи цепочки имен каталогов до корневого узла.
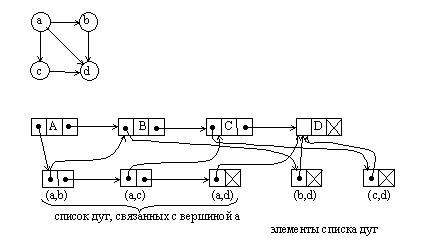
4.7. Представление графовГраф можно представить в виде списочной структуры, состоящей из списков двух типов √ списка вершин и списков ребер. Элемент списка вершин содержит поле данных и два указателя. Один указатель связывает данный элемент с элементом другой вершины. Другой указатель связывает элемент списка вершин со списком ребер, связанных с данной вершиной. Для ориентированного графа используют список дуг, исходящих из вершины. Элемент списка дуг состоит только из двух указателей. Первый указатель используется для того, чтобы показать в какую вершину дуга входит, а второй √ для связи элементов в списке дуг вершины.
Рис. 4.22. Представление графа в виде списочной структуры
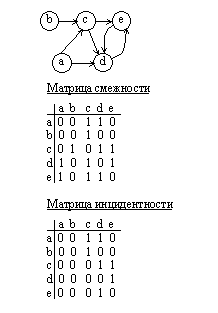
Очень распространенным является матричный способ представления графов. Для представления ненаправленных графов обычно используют матрицы смежности, а для ориентированных графов √ матрицы инцидентности. Обе матрицы имеют размерность n*n, где n-число вершин в графе. Вершины графа последовательно нумеруются.
Матрица смежности имеет значение ноль в позиции m (i,j), если не существует ребра, связывающего вершину i с вершиной j, или имеет единичное значение в позиции m (i,j), если такое ребро существует.
Правила построения матрицы инцидентности аналогичны правилам построения матрицы инцидентности. Разница состоит в том, что единица в позиции m (i,j) означает выход дуги из вершины i и вход дуги в вершину j.
Рис.4.23. Матричное представление графа
Поскольку матрица смежности симметрична относительно главной диагонали, то можно хранить и обрабатывать только часть матрицы. Можно заметить, что для хранения одного элемента матрицы достаточно выделить всего один бит.
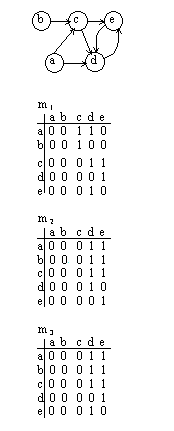
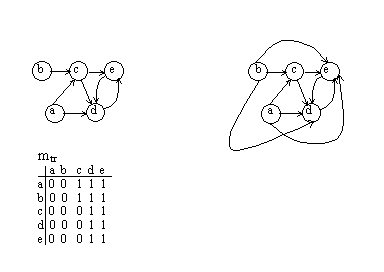
4.8. Алгоритмы на графахВ некоторых матричных алгоритмах обработки графов используются так называемые матрицы путей. Определим понятие пути в ориентированном графе. Под путем длиной k из вершины i в вершину j мы будем понимать возможность попасть из вершины i в вершину j за k переходов, каждому из которых соответствует одна дуга. Одна матрица путей m k содержит сведения о наличии всех путей одной длины k в графе. Единичное значение в позиции (i,j) означает наличие пути длины k из вершины i в вершину j.
Рис.4.24. Матрицы путей
Матрица m1 полностью совпадает с матрицей инцидентности. По матрице m 1 можно построить m 2 . По матрице m 2 можно построить m 3 и т. д. Если граф является ациклическим, то число мариц путей ограничено. В противном случае матрицы будут повторяться до бесконечности с некоторым периодом, связанным с длиной циклов. Матрицы путей не имеет смысла вычислять до бесконечности. Достаточно остановиться в случае повторения матриц.
Если выполнить логическое сложение всех матриц путей, то получится транзитивное замыкание графа.
M tr = m 1 OR m 2 OR m 3 ┘
В результате матрица будет содержать все возможные пути в графе.
Рис. 4.25. Транзитивное замыкание в графе
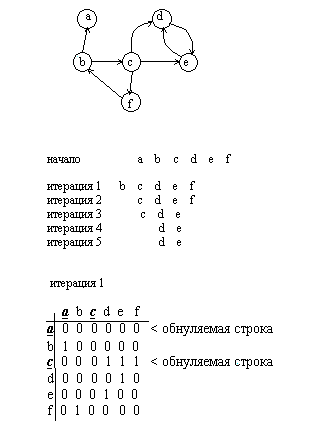
Наличие циклов в графе можно определить с помощью эффективного алгоритма. Алгоритм может быть реализован как для матричного, так и для спискового способа представления графа.
Принцип выделения циклов следующий. Если вершина имеет только входные или только выходные дуги, то она явно не входит ни в один цикл. Можно удалить все такие вершины из графа вместе со связанными с ними дугами. В результате появятся новые вершины, имеющие только входные или выходные дуги. Они также удаляются. Итерации повторяются до тех пор, пока граф не перестанет изменяться. Отсутствие изменений свидетельствует об отсутствии циклов, если все вершины были удалены. Все оставшиеся вершины обязательно принадлежат циклам.
Сформулируем алгоритм в матричном виде
- Для i от 1 до n выполнить шаги 1-2
- Если строка M(i ,*) = 0, то обнулить столбец i
- Если столбец M(*, i) = 0, то обнулить строку i
- Если матрица изменилась, то выполнить шаг 1
- Если матрица нулевая, то стоп, граф ациклический, иначе матрица содержит вершины, входящие в циклы
Рис. 4.26. Поиск циклов в графе
Достоинством данного алгоритма является то, что происходит одновременное определение цикличности или ацикличности графа и формирование списка вершин, входящих в циклы. В матричной реализации после завершения алгоритма остается матрица инцидентности, соответствующая подграфу, содержащему все циклы исходного графа.